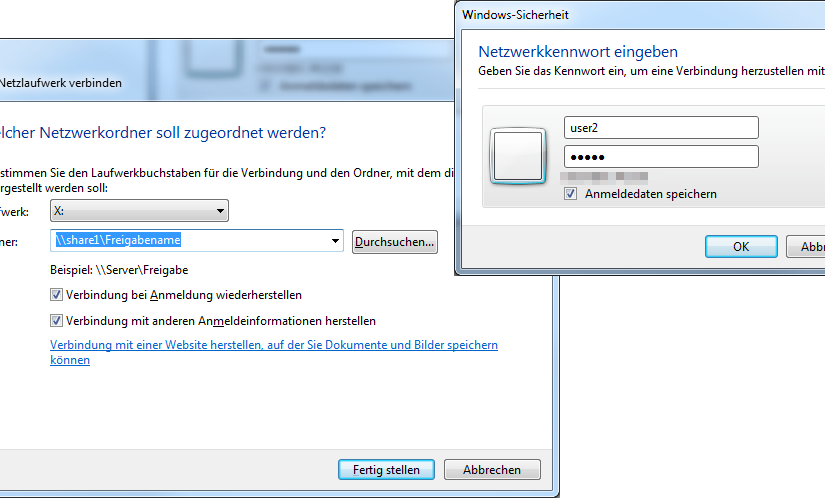
Ich hatte heute (mal wieder) das Problem, dass ich Netzlaufwerke mit unterschiedlichen Benutzerdaten auf einem Rechner einrichten muss.
Das Szenario: Ein PC greift mit user1:user1 auf verschiedene Shares zu, soll aber mit user2:user2 auf andere Shares auf dem selben Host zugreifen.

Quick Analysis: News websites blocking AI bots
I have wanted to see how many news websites have blocked the AI Bots so far using the Disallow rules.
To get some usefule website data, I have checked on Github and found this repository: news-hub by Pr0gramWizard. It includes an SQL file with a lot of websites and their respective categories.
I have used the data contained within that SQL file and filtered for “news” websites.
See how many news publishers are blocking AI botsFind non-lazy-loaded images with ScreamingFrog custom extraction
If you need this, and you’re using ScreamingFrog for this, you know how to use it 🙂 No explanation, no how-to, here’s the regex to use in your custom extraction in ScreamingFrog.
<\s*img(?![^>]*loading)[^>]*src\s*=\s*["']([^"']+)["'][^>]*>Code-Sprache: JavaScript (javascript)Note: This only works with “simple” HTML <img> tags, not srcsets. Sorry. This was enough to get the job done for me.
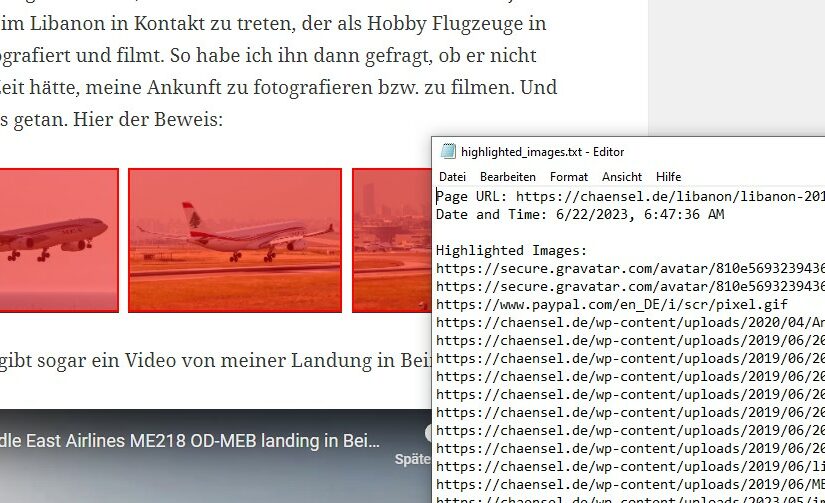
SEO Bookmarklet: Find images without alt attribute
Here’s a quick one for you SEO folks out there.
This browser bookmarklet will highlight all images without an “alt” attribute and those with an empty alt attribute in red, and download a list of the images.
It will help you get a very quick overview over where the alt attributes are missing, so you can easily edit them without having to check each image manually.
javascript:(function() {
var images = document.getElementsByTagName('img');
var highlightedImages = [];
for (var i = 0; i < images.length; i++) {
var image = images[i];
var altText = image.getAttribute('alt');
if (!altText || altText.trim() === '') {
image.style.border = '2px solid red';
var overlay = document.createElement('div');
overlay.style.position = 'absolute';
overlay.style.top = image.offsetTop + 'px';
overlay.style.left = image.offsetLeft + 'px';
overlay.style.width = image.offsetWidth + 'px';
overlay.style.height = image.offsetHeight + 'px';
overlay.style.background = 'rgba(255, 0, 0, 0.5)';
overlay.style.pointerEvents = 'none';
image.parentNode.insertBefore(overlay, image);
highlightedImages.push(image.src);
}
}
console.log('Highlighted Images:', highlightedImages);
var date = new Date();
var dateString = date.toLocaleString();
var content = 'Page URL: ' + window.location.href + '\n';
content += 'Date and Time: ' + dateString + '\n\n';
content += 'Highlighted Images:\n' + highlightedImages.join('\n');
var blob = new Blob([content], { type: 'text/plain' });
var link = document.createElement('a');
link.download = 'highlighted_images.txt';
link.href = URL.createObjectURL(blob);
link.click();
})();
Code-Sprache: JavaScript (javascript)I also have a list of really cool SEO bookmarklets – check it out!

How to easily find CSS above the fold for your entire website quickly
Stylesheets included via link tags can cause rendering delays because the browser waits for the CSS to be fully downloaded and parsed before displaying any content. This can result in significant delays, especially for users on high latency networks like mobile connections.
To optimize page loading, PageSpeed recommends splitting your CSS into two parts. The first part should be in-line and responsible for styling the content that appears above the fold (initially visible portion of the page). The remaining CSS can be deferred and loaded later, reducing the impact on initial page rendering.
Optimize your ATF CSS
CSS-Optimierung: Ganz einfach das CSS above-the-fold finden.
Ja, wir wissen alle, dass wir unser CSS optimieren sollten. Das sog. “Crucial CSS”, also die wichtigsten Klassen, sollten wir inline einbauen, und den Rest der Stylesheets deferen. Aber wie findet man einfach die CSS-Klassen, die above the fold genutzt werden?

The best SEO bookmarklets
This is my list of the best SEO bookmarklets to use. My focus is on technical SEO, so this list will most likely contain many SEO bookmarklets which fall into the technical topic.
See my list of useful SEO bookmarklets
Bookmarklet: Compare SERP titles to actual onpage titles and h1 heading
aka: the #titlegeddon bookmarklet
Google has stirred up some dust all around the SEO world with their rewriting of websites‘ titles.
SEO folks are now trying to figure out how Google is rewriting their titles.
Get the Titlegeddon SEO bookmarklet
Use Google Sheets to pull website data for your SEO game
Google Sheets is my love. They haven’t been before – to be honest: I avoided spreadsheets as much as I could. But ever since I started my current job, I have learned to love working with spreadsheets.
Lately, I have been playing around with Google Sheets to get a quick overview of live webpage data without using any other tools.
Learn to use IMPORTXML for SEO
Inhaltsverzeichnis für die Schule
Da wir das selbst auch immer mal wieder benötigen, habe ich hier einmal die Vorlage für ein Inhaltsverzeichnis für die Schule hochgeladen.
Hier sind zwei Versionen der Inhaltsverzeichnis-Vorlage zum Ausdrucken im Format DIN A4. Einmal als Word-Dokument, und einmal als PDF-Datei.
Das Inhaltsverzeichnis hat auf der Hauptseite 19 Zeilen für die Inhaltsangaben.
| Seitenzahl: | 1 Hauptseite, 1 Folgeseite |
| Zeilenzahl: | Hauptseite: 19 Zeilen Folgeseite: 23 Zeilen |
| Vorlagenart: | PDF oder Word-Dokument |
| Papiergröße: | DIN A4 |