
Have you heard about the Tech SEO Summit Hamburg, Germany? And you’re not sure if you should just buy a ticket and go? Well, let me help you.
Find out if it is for youAutor: Christian Hänsel

Warum Unternehmen ihre eigenen Probleme nicht sehen können
Unternehmen wissen heute mehr über ihre Nutzer als je zuvor. Sie messen Klicks, analysieren Verhalten, verfolgen jede Interaktion. Und doch bleiben die entscheidenden Probleme oft unsichtbar. Kunden verstehen Prozesse nicht, suchen nach Antworten, brechen ab. Nicht, weil die Daten fehlen. Sondern weil Organisationen strukturell blind sind für das, was außerhalb ihrer eigenen Systeme passiert.
Es gehört zu den großen Selbstverständlichkeiten der digitalen Wirtschaft, dass alles messbar ist. Jeder Klick, jede Bewegung, jede Entscheidung hinterlässt eine Spur. Aus diesen Spuren entstehen Dashboards, aus Dashboards entstehen Entscheidungen.
So zumindest die Annahme.
Warum Unternehmen ihre eigenen Probleme nicht sehen können weiterlesen
Was Suchanfragen über die Qualität digitaler Systeme verraten
Über viele Jahre hinweg wurden Suchanfragen vor allem als Marketingdaten interpretiert. Sie galten als Indikator für Nachfrage, für Sichtbarkeit, für Reichweite. Wer häufig gesucht wurde, war relevant. Wer gut rankte, war erfolgreich.
Diese Logik hat das Denken ganzer Branchen geprägt.
Doch sie greift zu kurz.
Denn jede Suchanfrage erzählt auch eine andere Geschichte. Sie ist nicht nur Ausdruck von Interesse. Sie ist oft ein Hinweis darauf, dass ein Nutzer eine Information nicht dort gefunden hat, wo sie eigentlich verfügbar sein sollte.
Wer beginnt zu suchen, hat bereits ein Problem.
Was Suchanfragen über die Qualität digitaler Systeme verraten weiterlesen
Die Zeit vor WebMCP: Wie Websites schon heute KI-lesbar werden
Das Web steht vor einer neuen Schnittstelle.
Über zwei Jahrzehnte lang war klar, wie Informationen im Internet gefunden werden: Suchmaschinen indexierten Webseiten, berechneten Rankings und präsentierten eine Liste mit Links. Nutzer klickten sich durch diese Ergebnisse, bis sie die gewünschte Information fanden.
Dieses Modell verändert sich gerade grundlegend.
Immer häufiger stellen Menschen ihre Fragen direkt einem KI-System. Statt (wie früher) zehn Suchergebnisse zu vergleichen, formulieren sie eine Anfrage wie „Business-Hotel nahe der Messe Düsseldorf mit schnellem WLAN“ oder „beste Verbindung von Berlin nach Zürich morgen früh“. Die Antwort kommt nicht mehr als Liste von Links, sondern als zusammengefasste Empfehlung.
Für Websites entsteht daraus eine neue Realität. Sie werden nicht mehr nur als Zielseite besucht. Sie werden zunehmend zu Wissensquellen, aus denen KI-Systeme Informationen extrahieren.
Die Zeit vor WebMCP: Wie Websites schon heute KI-lesbar werden weiterlesen
Warum Unternehmen jetzt über WebMCP nachdenken sollten
In der Diskussion über KI-Assistenten entsteht derzeit ein neues Schlagwort: WebMCP.
Das „Model Context Protocol“ soll es KI-Systemen ermöglichen, direkt mit Websites und Web-Anwendungen zu interagieren.
Statt Informationen nur zu lesen, könnten Assistenten Tools auf Webseiten nutzen: Verfügbarkeiten prüfen, Produkte konfigurieren, Buchungen vorbereiten.
Technisch wirkt diese Vision nicht mehr weit entfernt.
Doch zwischen einer neuen Webtechnologie und ihrer realen Nutzung in Unternehmen liegt oft ein weiter Weg.

Wenn KI die Reise plant: Was das für Hotels und Airlines bedeutet
Über viele Jahre begann eine Reiseplanung mit einer Suchmaschine.
Reisende gaben ein paar Stichworte ein, öffneten mehrere Tabs und verglichen Flüge, Hotels und Preise. Online-Reiseplattformen sammelten den Traffic ein, Airlines und Hotels zahlten Provisionen, und Suchmaschinen entschieden darüber, wer sichtbar war.
Dieses Modell funktionierte erstaunlich stabil.
Doch gerade verändert sich die Logik der Reiseplanung.
Immer häufiger formulieren Nutzer keine Suchanfragen mehr, sondern Fragen. Sie beschreiben ihre Situation einem KI-Assistenten: wann sie reisen möchten, wohin sie fliegen wollen, ob sie geschäftlich unterwegs sind oder mit Familie.
„Ich muss nächste Woche nach München zur Messe. Welcher Flug ist sinnvoll – und welches Hotel ist ruhig, aber nah am Messegelände?“
Aus dieser Anfrage entsteht keine Liste von zehn Links.
Es entsteht eine Empfehlung.
Für Airlines und Hotels verschiebt sich damit eine zentrale Frage der digitalen Sichtbarkeit. Nicht mehr: Auf welcher Position erscheine ich in der Suche?
Sondern: Werde ich vom System überhaupt als passende Option erkannt?
Was bedeutet das für Airlines und Hotels?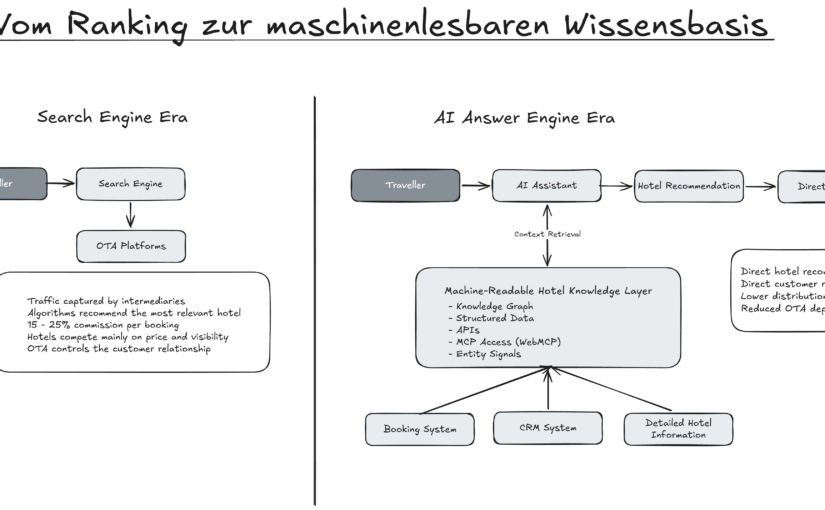
Von OTA-Abhängigkeit zu KI-Distribution: Warum Hotels ihre Datenstrategie jetzt neu denken müssen
Zwei Jahrzehnte lang funktionierte Hotelvertrieb im Internet nach einem einfachen Muster: Gäste suchten bei Google, Online-Reiseplattformen sammelten den Traffic ein, und Hotels zahlten Provision. Für viele Häuser wurde dieses Modell zur festen Realität. Wer sichtbar sein wollte, musste dort erscheinen, wo Reisende ihre Suche begannen. Und wer Buchungen wollte, akzeptierte Provisionen von oft 15 bis 25 Prozent.
Doch gerade verändert sich die Logik der Suche.
Wie Hotels sich digital für die Zukunft positionieren müssenIch habe aufgeräumt
Vieles kommt neu. Manches kommt gar nicht mehr.
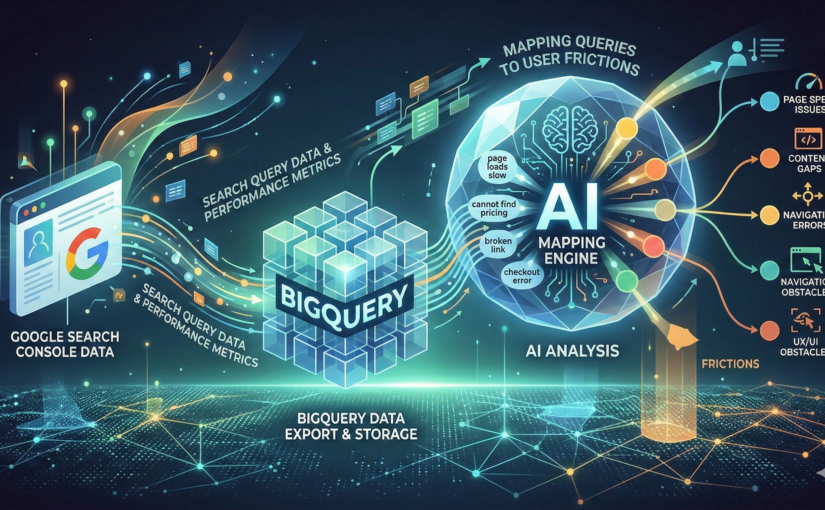
Externe Suchdaten als Diagnose für digitale Benutzerführung
Dieser Beitrag wird etwas über die Grenzen der reinen Suchmaschinenoptimierung hinausgehen. Aber tun wir SEOs das nicht immer – über den Tellerrand blicken, auf die User, den Intent, die Nutzbarkeit und Nutzung der Website?
Also ist es vermutlich gar nicht so schlimm, dass ich dich hier mit auf eine kleine Reise raus aus dem reinen SEO-Land und hinein in das liebliche Land der Friktionen entführe.
So nutzt du GSC-Daten als Diagnose für Probleme in der Benutzerführung
Martha Dünker – eine Lemgoerin mit Geschichte
In meiner Heimatstadt Lemgo gibt es – wie in vielen anderen Städten auch – einige Menschen, die nicht so recht in das Stadtbild passen, da sie sich nicht anpassen und am „normalen Leben“ teilhaben.
So scheint es auch Martha Dünker ergangen zu sein, die in Lemgo zwar sehr bekannt war, aber von nur sehr wenigen Menschen wirklich gekannt wurde.
Erfahre mehr über Martha Dünker