Dieser Beitrag wird etwas über die Grenzen der reinen Suchmaschinenoptimierung hinausgehen. Aber tun wir SEOs das nicht immer – über den Tellerrand blicken, auf die User, den Intent, die Nutzbarkeit und Nutzung der Website?
Also ist es vermutlich gar nicht so schlimm, dass ich dich hier mit auf eine kleine Reise raus aus dem reinen SEO-Land und hinein in das liebliche Land der Friktionen entführe.
Daten, Daten, Daten
Ich kenne einige SEOs, die so sind wie ich. Ich liebe Daten. Daten in jeder Form (am liebsten sauber strukturiert, vollständig und in passender Kodierung – ich schweife ab…), gerne viele Daten, und sehr gerne aussagekräftige Daten.
Was machen wir SEOs mit Daten? Es gibt ja vielfältige Beschäftigungsmöglichkeiten. Wir nutzen Sistrix-Daten, um Rankings und Veränderungen in der Sichtbarkeit zu erkennen. Wir nutzen ahrefs, um Backlinkdaten zu bekommen (und zahlen teuer dafür). Wir nutzen Logfiles (oder: sollten sie nutzen), um zum Beispiel Crawling-Patterns und Fehler zu sehen, die wir in anderen Tools und Dashboards so nicht sehen.
Und wir nutzen die eine Datenquelle, die uns vermeintlich die validesten Suchdaten bereitstellt: Die Google Search Console.
Für was kann man die Search Console nicht alles nutzen! Dieses kleine, wundervolle Geschenk Googles ( /s ) erlaubt es uns, in die Tiefen der Suchanfragen und Rankings einzutauchen und genau zu verstehen, wonach die User suchen, wenn sie auf unsere Seite finden. Okay.. wieder ein /s an dieser Stelle. Ja, /s bedeutet /sarcasm.
Die Search Console ist ein netter Einstiegspunkt, aber die Daten sind eher unbrauchbar, wenn man wirklich in die Tiefe gehen möchte. WIr sehen eine starke Limitierung in der Zielenanzahl, eher schlechte Longtail-Abdeckung, Aggregierte Darstellung ähnlicher Queries und das Unter-den-Tisch-Fallen seltener Anfragen.
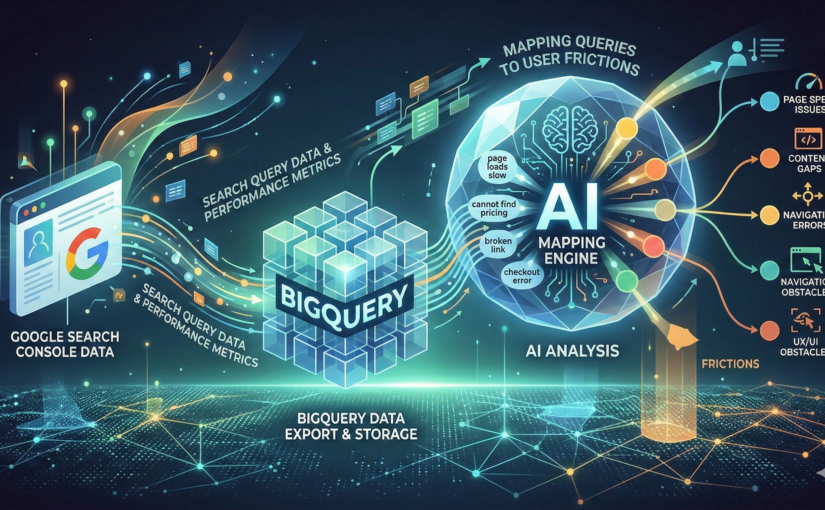
Hier kommt ein schönes Feature zum Tragen, das (eigentlich) jeder SEO nutzen sollte: Den GSC-BigQuery-Export. Wie das aufzusetzen ist, solltest du googlen können.
Der BigQuery-Export gibt uns deutlich vollständigere Daten, keine UI-bedingte Zeilenbegrenzung, keine aggresive Voraggregation und lässt uns die Daten historisch speichern – auch länger als die 16 Monate, die uns in der GSC UI zur Verfügung stehen.
Nutzung der GSC-Daten zur Diagnose
Nutzen wir die GSC-Daten aus BigQuery anders als im regulären SEO-Kontext, können wir Muster erkennen, die uns helfen, die Benutzerführung und (hier kommen wir in die Operations-Ebene) die Friktionspunkte im System zu erkennnen.
Im klassischen SEO schauen wir auf Position, CTR, Impressions, URL-Performance und manchmal sogar noch nach Kannibalisierung.
Für Friktionsdiagnostik interessieren uns andere Fragen:
- Welche semantisch ähnlichen Anfragen häufen sich?
- Welche Unsicherheiten wiederholen sich sprachlich?
- Wo entstehen Varianten desselben Problems?
Und hier wird es technisch interessant.
Warum einfaches Keyword-Grouping nicht reicht
Früher hätte man vielleicht mit Regex oder Ähnlichkeitsbestimmungen gearbeitet:
- LIKE ‚%refund%‘
- LIKE ‚%boarding pass%‘
- LIKE ‚%payment failed%‘
Das funktioniert, aber nur grob und in meinem Augen relativ unbrauchbar.
Das Problem: Friktion ist sprachlich fragmentiert.
Beispiele:
- „refund after delay“
- „compensation eligibility“
- „how long refund takes“
- „refund status not updated“
- „can I claim money for flight delay“
Keines dieser Beispiele enthält exakt dieselben Begriffe.
Aber semantisch beschreiben sie denselben Unsicherheitsraum.
RegEx reicht hier nicht.
Clustering via Embeddings
Statt Keywords zu matchen, kann man Queries als semantische Vektoren modellieren.
Kurz erklärt:
- Jedes Query wird durch ein Sprachmodell (z.B: sentence-transformers/paraphrase-multilingual-mpnet-base-v2 in einen Embedding-Vektor überführt.
- Ähnliche Anfragen liegen im Vektorraum nah beieinander.
- Unterschiedliche Themen liegen weiter auseinander.
Technisch bedeutet das:
- Export der Query-Daten aus BigQuery
- Generierung von Embeddings (z. B. lokal auf Deinem Rechner oder, wenn Du zuviel Geld hast, via OpenAI, Vertex AI, etc.)
- Speicherung der Vektoren
- Clustering mit Verfahren wie:
- k-means
- HDBSCAN
- hierarchisches Clustering
Das Ergebnis sind keine Keyword-Listen mehr.
Sondern thematische Friktionsräume.
Beispiel: Refund-Cluster
Ein Embedding-basiertes Clustering könnte automatisch folgende Queries gruppieren:
- „request refund for delayed flight“
- „flight rescheduled compensation eligibility“
- „how to claim delay compensation“
- „refund after cancellation by airline“
Obwohl die Formulierungen unterschiedlich sind, erkennt das Modell:
→ gleiches Intent-Feld
→ gleiches Unsicherheitsmuster
→ gleicher potenzieller Friktionspunkt
Das ist qualitativ etwas völlig anderes als ein Keyword-Filter.
Bestimmung von Friktion via KI-Klassifikation
Clustering zeigt uns Gruppen.
Aber nicht jede Gruppe ist automatisch Friktion.
Deshalb kann man einen zweiten Schritt einführen:
Intent- oder Friktionsklassifikation via LLM
Beispielsweise mit einem strukturierten Prompt wie:
- Handelt es sich um Navigationssuche?
- Handelt es sich um Status-Unsicherheit?
- Handelt es sich um Policy-Unklarheit?
- Handelt es sich um Error-Recovery?
- Handelt es sich um reine Information?
So entsteht:
Query → Embedding → Cluster → KI-Klassifikation → Friktionstyp
Das erlaubt:
- quantitative Auswertung pro Friktionscluster
- Priorisierung nach Volumen
- Kombination mit Support-Kosten
- Identifikation systemischer Schwachstellen
Warum das operativ relevant ist
Der Unterschied zu klassischem SEO ist fundamental.
Wir optimieren nicht: „Wie ranken wir für dieses Keyword?“
Wir analysieren: „Warum zwingt unser System Nutzer, diese Frage extern zu stellen?“
Wenn sich z. B. ein großes Cluster rund um:
- Refund Eligibility
- Delay Compensation
- Status of Refund
bildet, dann ist das kein SEO-Potenzial.
Das ist ein Hinweis auf:
- unklare Policy-Kommunikation
- mangelnde Sichtbarkeit im Self-Service
- fehlende Prozess-Transparenz
Und damit ein operatives Thema.
Wichtig: Kein Heilsversprechen
Embeddings und KI sind hier kein magischer Wahrheitsgenerator.
Sie helfen bei:
- Strukturierung großer Datenmengen
- Erkennen semantischer Muster
- Skalierung der Analyse
Die Interpretation bleibt immer menschlich. Aber ohne diese Techniken bleibt man im Long-Tail-Nebel stecken.
Wir können mit dieser Methode relativ einfach und automatisiert (<3 Python und Co.) monatliche Friktionsmuster aufdecken, die in unsere Roadmap-Planung einfließen kann, um unsere User bestmöglich in unseren digitalen Assets „an die Hand zu nehmen“, zu führen, den Self-Service zu verbessern und somit interne Kosten einzusparen, indem man durch passende Informationen und guiding Content das Support-Aufkommen durch ratlose User minimiert.